

🦿 強化学習を用いた歩行ポリシーのトレーニング#
Genesis は並列シミュレーションをサポートしており、強化学習(RL)の歩行ポリシーを効率的にトレーニングするのに最適です。このチュートリアルでは、Unitree Go2 ロボットが歩行できる基本的な歩行ポリシーを取得するための完全なトレーニング例を紹介します。
これは Genesis で非常に基本的な RL トレーニングパイプラインを示すシンプルで最小限の例です。この例を使用することで、すぐに実機の四足歩行ロボットに展開可能な歩行ポリシーを取得することができます。
注意: これは包括的な歩行ポリシーのトレーニングパイプラインでは ありません。簡略化された報酬項目を使用して入門を容易にするものであり、大規模バッチサイズにおける Genesis のスピードを最大限に活用するものではありません。そのため、基本的なデモンストレーション用途に限定されます。
謝辞: このチュートリアルは、Legged Gym のいくつかの基本概念に着想を得て、それらを活用しています。
環境の概要#
まず、ジムスタイルの環境(go2-env)を作成します。
初期化#
__init__ 関数は以下の手順でシミュレーション環境を設定します:
制御周波数
シミュレーションは 50 Hz で動作し、実機ロボットの制御周波数に合わせています。また、リアルロボットで観測される行動遅延(約20ms、1ステップ)を手動でシミュレートすることで、シミュレーションと実機のギャップを埋めています。シーンの作成
ロボットと静的平面を含むシミュレーションシーンを作成します。PD コントローラーのセットアップ
モーターは名前を基に識別され、各モーターの剛性と減衰が設定されます。報酬の登録
ポリシーを誘導するために、設定に定義された報酬関数を登録します。これらの関数は「報酬」のセクションで説明します。バッファの初期化
環境状態、観測、報酬を格納するためのバッファを初期化します。
リセット#
reset_idx 関数は、指定した環境の初期姿勢および状態バッファをリセットします。これにより、ロボットは事前定義された構成から開始でき、一貫したトレーニングが可能になります。
ステップ#
step 関数は、行動を実行して新しい観測と報酬を返します。以下のように動作します:
行動の実行
入力された行動をクリップし、再スケールして、デフォルトのモーター位置に追加します。この変換後の行動は目標関節位置を表し、ロボットのコントローラーに送信されて1ステップ実行されます。状態の更新
関節位置や速度などのロボットの状態を取得してバッファに格納します。終了条件のチェック
(1) エピソードの長さが最大許容値を超える場合、(2) ロボットの本体の向きが大きく逸れた場合に環境を終了します。終了した環境は自動的にリセットされます。報酬の計算
観測の計算
トレーニングに使用する観測には、基礎の角速度、投影重力、コマンド、関節位置、関節速度、過去の行動が含まれます。
報酬#
報酬関数はポリシーの誘導にとって重要です。この例では以下を使用します:
tracking_lin_vel: 線形速度コマンド(xy軸)の追従
tracking_ang_vel: 角速度コマンド(yaw)の追従
lin_vel_z: z軸の基礎線形速度をペナルティ
action_rate: 行動の変化をペナルティ
base_height: 基礎の高さが目標から逸れることに対するペナルティ
similar_to_default: ロボットの姿勢がデフォルト姿勢に近いことを奨励
トレーニング#
ここまでで環境を定義しました。次に、rsl-rl の PPO 実装を使用してポリシーをトレーニングします。pip 経由で Python の依存関係をインストールしてください:
# tensorboard と rsl_rl をインストール
pip install tensorboard rsl-rl-lib==2.2.4
インストール後、以下のコマンドでトレーニングを開始します:
python examples/locomotion/go2_train.py
トレーニングプロセスをモニターするには、TensorBoard を起動します:
tensorboard --logdir logs
次のようなトレーニング曲線が表示されるはずです:
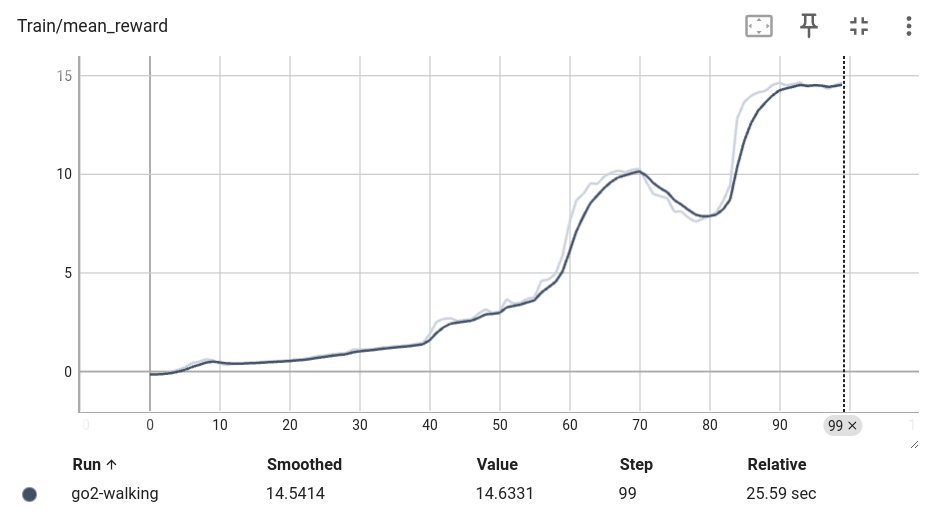
評価#
最後に、トレーニング済みポリシーをロールアウトします。以下のコマンドを実行してください:
python examples/locomotion/go2_eval.py
次のような GUI が表示されるはずです:
もし実物の Unitree Go2 ロボットをお持ちであれば、ポリシーを展開することができます。楽しんでください!