

🚁 強化学習を用いたドローンホバリングポリシーのトレーニング#
Genesis は並列シミュレーションをサポートしており、強化学習(RL)のドローンホバリングポリシーを効率的にトレーニングするのに最適です。このチュートリアルでは、ランダムに生成されたターゲットポイントに到達することで安定したホバリング位置を維持する基本的なホバリングポリシーを取得するための完全なトレーニング例を紹介します。
これは Genesis で非常に基本的な RL トレーニングパイプラインを示すシンプルで最小限の例です。この例を使用することで、すぐに実機のドローンに展開可能なホバリングポリシーを取得することができます。
注意: これは包括的なドローンホバリングポリシーのトレーニングパイプラインでは ありません。簡略化された報酬項目を使用して入門を容易にするものであり、大規模バッチサイズにおける Genesis のスピードを最大限に活用するものではありません。そのため、基本的なデモンストレーション用途に限定されます。
謝辞: このチュートリアルは、Champion-level drone racing using deep reinforcement learning (Nature 2023) から着想を得て、そのアイデアを活用しています。
環境の概要#
まず、ジムスタイルの環境(hover-env)を作成します。
初期化#
__init__ 関数は以下の手順でシミュレーション環境を設定します:
制御周波数
シミュレーションは 100 Hz で動作し、ドローンに高周波制御ループを提供します。シーンの作成
ドローンと静的平面を含むシミュレーションシーンを作成します。ターゲットの初期化
ドローンが到達しようとするランダムなターゲットポイントを初期化します。報酬の登録
ポリシーを導くために、あらかじめ定義された報酬関数を登録します。これらの関数は「報酬」のセクションで説明します。バッファの初期化
環境状態、観測、報酬を格納するためのバッファを初期化します。
リセット#
reset_idx 関数は、指定した環境の初期姿勢および状態バッファをリセットします。これにより、ロボットは事前定義された構成から開始でき、一貫したトレーニングが可能になります。
ステップ#
step 関数は、行動を実行して新しい観測と報酬を返します。以下のように動作します:
行動の実行
入力された行動をクリップし、再スケールして、デフォルトのホバリングプロペラ RPM に調整として適用します。状態の更新
ドローンの状態(位置、姿勢、速度など)を取得してバッファに格納します。終了条件のチェック
終了した環境は自動的にリセットされます。以下の条件を満たす場合、環境は終了されます:エピソードの長さが最大許容値を超える。
ドローンのピッチ角またはロール角が指定された閾値を超える。
ドローンの位置が指定された境界を超える。
ドローンが地面に近すぎる。
報酬の計算
ドローンがターゲットポイントに到達し、安定性を維持するパフォーマンスに基づいて報酬を計算します。観測の計算
観測値は正規化され、ポリシーに返されます。トレーニングに使用される観測値には、ドローンの位置、姿勢(四元数)、機体の線速度、機体の角速度、過去の行動が含まれます。
報酬#
報酬関数はポリシーの誘導にとって重要です。この例では以下の報酬関数を使用して、ドローンがターゲットポイントに到達し、安定性を維持するように促します:
target: ドローンがランダムに生成されたターゲットポイントに到達するように促します
smooth: 平滑で制御された動きを促します。
yaw: ドローンが安定したホバリング姿勢を維持するように促します
angular: ドローンが低い角速度を維持するように促します
crash: ドローンがクラッシュしたり、ターゲットから大きく離れた場合に適用されるペナルティ
これらの報酬関数は組み合わされて、ポリシーに包括的なフィードバックを提供し、安定で正確なホバリング動作を実現するように誘導します。
トレーニング#
ここまでで環境を定義しました。次に、rsl-rl の PPO 実装を使用してドローンホバリングポリシーをトレーニングします。以下のインストール手順に従ってください:
依存関係のインストール Genesis がインストールされていることを確認し、
pipを使用して必要な Python の依存関係をインストールします。# tensorboard と rsl_rl をインストール pip install --upgrade pip pip install tensorboard rsl-rl-lib==2.2.4
トレーニングスクリプトの実行. インストール後、以下のコマンドでトレーニングを開始します:
python hover_train.py -e drone-hovering -B 8192 --max_iterations 301
-e drone-hovering: 実験名を "drone-hovering" に指定します-B 8192: 並列トレーニングの環境数を 8192 に設定します--max_iterations 301: 最大トレーニング反復回数を 301 に指定します-v: オプション。可視化を有効にしてトレーニングを行います
トレーニングプロセスをモニターするには、TensorBoard を起動します:
tensorboard --logdir logs
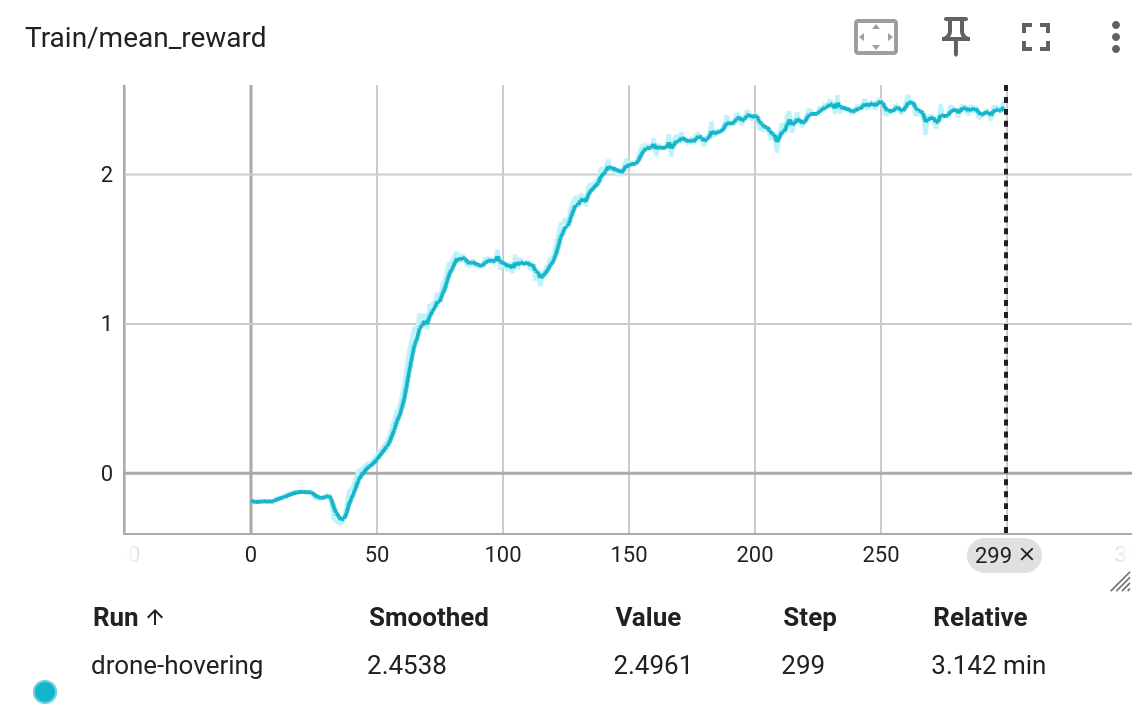
次のようなトレーニング曲線が表示されるはずです:
可視化を有効にしてトレーニングを行うと、次のような画面が表示されます:

評価#
トレーニングが完了したドローンホバリングポリシーを実行します。以下のコマンドを実行してください:
評価スクリプトの実行
提供された評価スクリプトでトレーニング済みのポリシーを評価します。python hover_eval.py -e drone-hovering --ckpt 300 --record
-e drone-hovering: 実験名を "drone-hovering" に指定します--ckpt 300: チェックポイント 300 からトレーニング済みのポリシーをロードします--record: 評価を記録し、ドローンのパフォーマンスのビデオを保存します
結果の可視化
評価スクリプトはドローンのパフォーマンスを可視化し、--recordフラグを使うとビデオを保存できます。
このチュートリアルに従うことで、Genesis を使用して基本的なドローンホバリングポリシーをトレーニングおよび評価することができます。楽しんでください!